Technical B2B Support in 2026: What Leaders Must Prepare For

In 2026, Tier 1 automation is table stakes. The real constraint is Tier 2 and 3 work—where the problem isn't answering questions, it's assembling context to debug safely and quickly.
T1 automation should be table stakes.
In 2026, automating Tier 1 is table stakes. The real constraint for technical B2B companies is Tier 2 and Tier 3 work, where the "problem" is not answering a question. The problem is assembling enough context to debug safely and quickly.
That shift changes what you should optimize, what you should measure, and where AI actually earns its keep.
The new bottleneck is context, not capability
Most T2/T3 time is spent before anyone can even start diagnosing:
- Which environment and version is this customer on?
- What configs and feature flags are enabled?
- What do the logs, traces, and metrics show?
- What changed recently (deploy, rollout, integration update)?
- Has Support or Engineering seen a similar pattern before?
This is why senior support feels like a scavenger hunt across ticketing, CRM, product admin, observability, incident tooling, and prior cases.

This is not a "support issue." It is an information flow issue. Atlassian's State of Teams 2025 report found teams spend about 25% of their time searching for information. Support engineers are a concentrated version of that problem.
AHT is being driven by "research minutes," not "fix minutes"
Average handle time (AHT) is a simple metric, but it still tells the story: it captures how long work takes end-to-end. In technical support, the part that quietly balloons is the research phase: assembling evidence and reproducing the issue.
So if you want to move AHT for T2/T3, you cannot only "speed up replies." You have to cut the time spent gathering context and re-gathering it again on the next similar escalation.
Tier 1 automation should be standard, but only if the knowledge is real
By 2026, "we automated T1" will not be a differentiator. It will be expected.
Vendors are already marketing very high automation rates. The practical takeaway for leaders is this:
- If your documentation and knowledge base are incomplete, stale, or hard to retrieve, your "T1 automation" will either fail silently or create trust problems.
- If your knowledge is strong and kept current, T1 becomes a workflow you can hand to AI with confidence.
What leaders should prepare for
1. Split the support world into two systems: T1 and T2/T3
Stop managing one blended workflow.
- T1 is best treated like a product surface: instant answers, consistent quality, and tight feedback loops.
- T2/T3 is best treated like an engineering-adjacent process: evidence, reproducibility, and fast handoffs.
This is also how you avoid the classic trap: celebrating T1 automation while your most expensive work (T2/T3) gets slower.
2. Measure the "time to first useful response," not just first response
A fast "we're looking" reply does not change outcomes. What matters is the first response that includes:
- Key facts (env/version/config)
- Evidence (log or trace pointers)
- A clear next step
This is where context automation shows up quickly in metrics and staffing models.
3. Make "context packets" a required artifact for escalations
The best T2/T3 teams already do this informally. In 2026, formalize it.
A context packet is a structured bundle created at ticket open or escalation time:
| Component | Description |
|---|---|
| Customer snapshot | Environment, version, account details |
| Config state | Relevant configs and recent changes |
| Observability data | Log and trace highlights |
| Pattern matching | Similar cases and known patterns |
| Next actions | Suggested diagnostic steps |
When this is automated, you reduce AHT without cutting corners, because you're removing searching, not thinking.
4. Treat solved work as a knowledge asset that compounds
Most orgs leak knowledge every day: solved work disappears into ticket threads.
Knowledge-Centered Service (KCS) has been pushing the core idea for years: capture what you learn in the solve workflow, then improve it over time so you do not re-solve the same problem repeatedly.
In 2026, the bar is higher:
- You need capture to happen continuously, not as a side project
- You need gaps detected automatically, not via quarterly audits
- You need updates drafted quickly, because your product changes weekly
5. "Human-agent teams" will be the operating model
Support leaders will increasingly manage a hybrid workforce: humans plus specialized agents for search, summarization, context gathering, and drafting.
Microsoft's Work Trend Index frames this as organizations redesigning work around human-agent teams. Support is one of the clearest places to apply it because the workflows are repeatable, measurable, and constrained by information access.
A practical 2026 playbook for technical support
If you want a concrete plan that maps to AHT:
| Step | Action |
|---|---|
| 1 | Automate T1 with an AI assistant grounded in your real documentation and KB |
| 2 | Instrument T2/T3 by measuring "first useful response time" and AHT separately from T1 |
| 3 | Automate context gathering across the systems your engineers actually use (ticketing, CRM, product admin, observability, prior cases) |
| 4 | Standardize escalation packets so Engineering gets the same evidence every time |
| 5 | Close the loop: every solved ticket should either confirm existing guidance or produce a draft update to make the next occurrence easier |
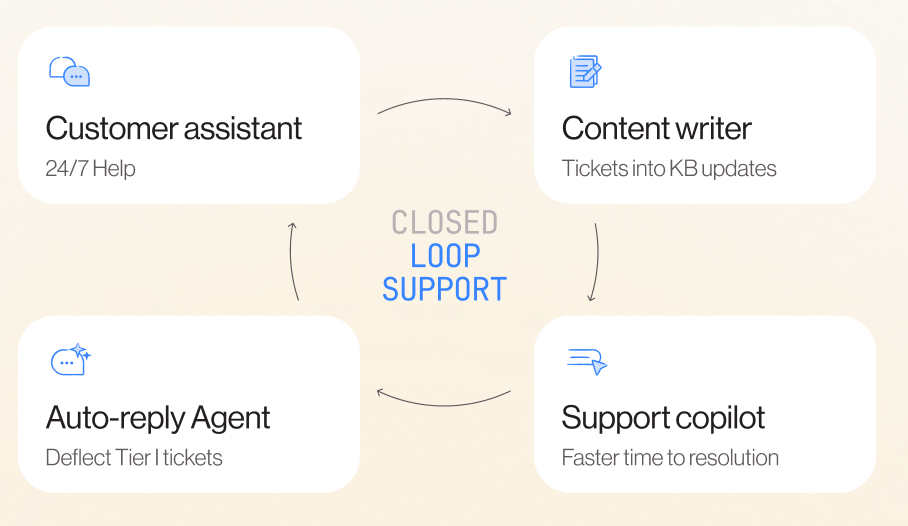
How Inkeep helps
Inkeep is built around the idea that support work should compound instead of repeating.
- AskAI handles Tier 1 by answering customer questions with responses grounded in your docs and knowledge base
- Agent Copilot integrates into support workflows to analyze tickets, surface the most relevant sources (docs, prior tickets, Slack), and draft suggested replies
- The content loop turns solved work into better future answers: when a ticket is solved, Inkeep can draft FAQs or doc updates so that novel learnings become documented guidance, and the next similar question is handled faster or fully self-served
If you want to win in 2026, the goal is simple: make Tier 1 fully self-serve, and make Tier 2/3 faster by eliminating the scavenger hunt and compounding what your team learns.




About the author

Frequently Asked Questions
Context, not capability. Most T2/T3 time is spent gathering information across systems before diagnosis can even begin.
Research minutes, not fix minutes. Assembling evidence and reproducing issues takes longer than the actual resolution.
Customer and environment snapshot, relevant configs, recent changes, log highlights, similar cases, and suggested next actions.
Treat T1 like a product surface (instant, consistent) and T2/T3 like an engineering process (evidence, reproducibility, fast handoffs).